Dynamiczne struktury danych
Wiadomosci wstępne
Istnieją bliskie analogie między metodami używanymi do strukturalizacji algorytmów oraz metodami używanymi do strukturalizacji danych. Oprócz analogii istnieją oczywiście także różnice. Gdyby ich nie było metody byłyby identyczne. Porównanie metod strukturalizacji programów i danych jest jednak zdecydowanie pouczające i kształcące.| Wzorzec konstrukcji | Instrukcja programu | Typ danych |
| Element podstawowy | Przypisanie | Typ skalarny |
| Wyliczenie | Instrukcja złożona | Typ rekordowy |
| Powtórzenie n razy | Instrukcja for | Typ rekordowy |
| Wybór | Instrukcja warunkowa | Rekord z wariantami |
| Powtórzenie ? razy | Instrukcja repeat, while | Ciąg lub typ plikowy |
| Rekurencja | Instrukcja procedury | Rekurencyjny typ danych |
| Ogólny "graf" | Instrukcja skoku | Struktura połączona wskaźnikami |
Lista jednokierunkowa "do przodu"
Jest to sposób wiązania (łączenia) zbioru elementów zbliżony do stosu. W celu odwołania się od dowolnego elementu do jego następnika konieczne jest tylko pojedyncze połączenie. Przedstawia to poniższy rysunek.
- wstawiać element do listy p o elemencie wyznaczonym przez p
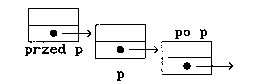
- wstawiać element do listy p r z e d elementem p
- usuwać z listy element znajdujący się p o p
- usuwać z listy element wskazywany przez p.
| type
TypDanych = String[44]; Wskaznik =^ElementListy. ElementListy = record K { Klucz } : Word; D { Dane } : TypDanych; N { Nast } : Wskaznik end; |
| procedure DopiszDoListy (var p :Wskaznik; Klucz :Word;
Dane :TypDanych);
var q : Wskaznik; begin New (q); { Powolujemy nowy element, na razie nie zwiazany z lista } q^.N := p; { Bedzie on wskazywal na element znajdujacy sie przed nim } p := q; { P - poczatek, pokaze nowo utworzony element } q^.K := Klucz; { Do nowego elementu wpiszemy wartosc jego klucza } q^.D := Dane { oraz inne dane, ktore beda w nim przechowywane } end; |
| procedure WstawPoElemencie (var p :Wskaznik; Klucz
:Word; Dane: TypDanych);
var q : Wskaznik; begin New (q); { Powolujemy nowy element, nie zwiazany na razie z lista } q^.N := p^.N; { Bedzie on wskazywal na to co wskazywal element p } q^.K := Klucz; { Wpisujemy do tego elementu odpowiedni klucz } q ^.D := Dane; { oraz dane, ktore chcemy w nim przechowywac } p^.N := q { p bedzie teraz wskazywalo na nowy element listy q } end; |
| procedure WstawPrzedElementem (var p :Wskaznik; Klucz :Word;
Dane:TypDanych);
var q : Wskaznik; begin New (q); { Powolujemy nowy element, nie zwiazany na razie z lista } q^ := p^; { Przepisujemy do niego w calosci to co bylo w p } p^.K := Klucz; { a do p przepisujemy nowy wprowadzany klucz } p^.D := Dane; { oraz dane, ktore chcemy w tam przechowywac } p^.N := q { p bedzie teraz wskazywalo na q ("stary" element) } end; |
| procedure UsunElementPo (var p :Wskaznik);
var r : Pointer; { Pomocniczy wskaznik pokazujacy na usuwany element } begin r:=p^.N; { Zapamietujemy wskaznik do usuwanego elementu } if r <> nil then { Jezeli nie chcemy skasowac elementu "za koncem" } begin { co jest n i e m o z 1 i w e , przepisujemy } p^.N:=p^.N^.N. { wskazanie z elementu wskazywanego przez p do p } Dispose(r) { a nastepnie likwidujemy usuwany element } end end; |
TypDanych określa jednoznacznie, jakie dane będą przechowywane na liście. W naszym przypadku będzie to łańcuch o magicznej długości 44.
ElementListy jest rekordem o trzech polach:
- D zawiera przechowywane dane
- K jest kluczem określającym pozycję elementu na liście
- N jest typu Wskaznik i pokazuje na kolejny element listy
Procedura DopiszDoListy służy do dopisywania nowych elementów do listy na jej początek (dokładniej przed ostatnio położony element), czyli jak gdyby przed początek listy. Parametrami procedury jest zmienna p wskazująca na początek listy i dwa parametry przekazywane przez wartość: klucz i dane wstawianego elementu listy. Procedura zwróci wskaźnik do nowego początku listy. Operacje wykonywane w tej procedurze są zbliżone do znanych nam ze stosu. Nie jest wykorzystywana jedynie instrukcja wiążąca. Na stercie rezerwujemy miejsce na nową zmienną dynamiczną q. Przepisujemy do niej wskazanie na poprzedni początek listy a następnie do parametru procedury p (początek listy!) przepisujemy q. Na koniec wpisujemy do q^ dane i klucz.
Zasadę działanie procedury WstawPoElemencie ilustruje poniższy rysunek. Pozostałe informacje zawarte są w komentarzach w procedurze.
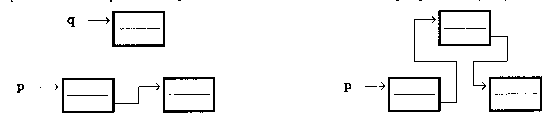

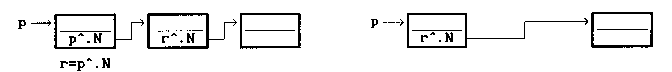
Inne podstawowe struktury danych
Przypomnijmy jeszcze raz, jakie dynamiczne struktury danych możemy zbudować:- stos (stack) to struktura danych, składająca się z liniowo uporządkowanych zbiorów składników (elementów), z których tylko "największy" jest w danej chwili dostępny. Miejsce dostępu to wierzchołek stosu. Jest to jedyne miejsce, do którego można dołączyć lub z którego można usunąć elementy.

- kolejka (queue) jest strukturą danych składającą się z liniowo uporządkowanych zbiorów składników, do której można dołączyć składnik tylko na jednym końcu (koniec kolejki), a usunąć tylko w drugim końcu (początek kolejki). Powiązanie między składnikami kolejki jest takie samo jak pomiędzy składnikami stosu.
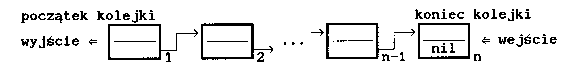
- lista jednokierunkowa ma organizację podobną do organizacji stosu i kolejki: dla każdego składnika, poza ostatnim, jest określony składnik następny lub dla każdego składnika, poza pierwszym, określony jest składnik poprzedni. Możliwe są dwa kierunki budowy.
- "do przodu"
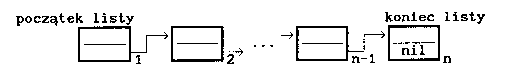
- "do tyłu"
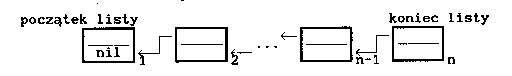
- lista dwukierunkowa to liniowo uporządkowany zbiór składników, w którym dla każdego składnika, poza pierwszym i ostatnim, jest określony składnik poprzedni i następny. Dla ostatniego składnika listy dwukierunkowej jest określony składnik poprzedni, a dla pierwszego - następny.

- lista cykliczna powstaje z listy jedno- lub dwukierunkowej przez powiązanie ostatniego składnika listy z jej pierwszym składnikiem. W wyniku takiego powiązania wyróżniane dotąd składniki pierwszy i ostatni przestają pełnić swoje funkcje. W liście cyklicznej żaden składnik nie jest wyróżniony.